

Working with Text Data - Tokenization
Most Important Concept You Must Know to Learn LLMs

With the rise in LLMs-based developments, where you can build an application (using prompts) with Open Source or Closed-Source Gen-AI models, in a few-weeks, which would have conventionally took several months.
This leap in efficiency is fueled by the large amounts of unlabeled and self-supervised data on which these models are trained, enabling them to produces generalizable and adaptable output.
In today’s article, we’ll explore tokenization—a critical process in preparing text data for LLMs—to understand how these models handle and process textual input to deliver accurate and meaningful outputs.
Understanding Tokenization
If you’ve been in the data field for quite some time, you’ve probably know that any NLP or LLM model requires numerical input.
Therefore, Text Vectorization or Token Embedding is required to converts textual data into numerical format, enabling the model to process and analyze it effectively.

Why do we need Feature Extraction from Text?
Text vectorization captures important information (representation) from sequential text data, such as word frequency, relationships between words, semantic and syntactic meaning, allowing models to learn patterns and generate accurate results.
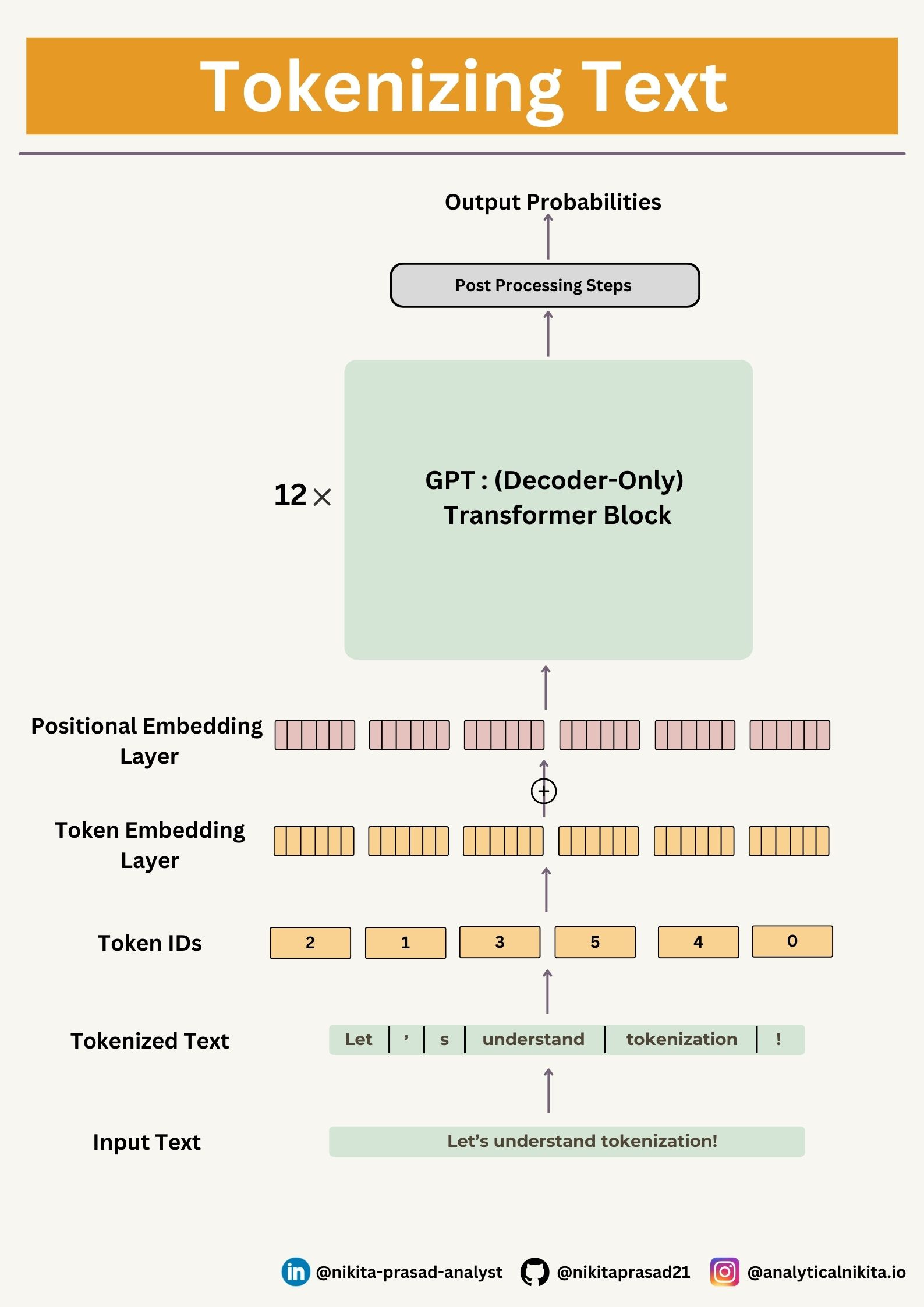
That’s what the tokenizers do, and there are a lot of ways to go about this — and, if possible, to find the computations friendly smallest representations.
Now, let’s import our dataset for understanding this in a better way.
» Importing Text Data
The dataset we will work with is, The Awakening by Kate Chopin, a public domain short story (for understanding purposes), written in 1899, so there is no copyright on that.
Note: It is recommended to be aware and respectful of existing copyrights and people privacy, while preparing datasets for training LLMs.

The goal is to tokenize this input text and embed this for an LLM
How can we best split this text to obtain a list of tokens?
Let’s take a look at three common types of tokenization algorithms, and simultaneously try to answer some of the questions you may have about tokenization.
01. Character-Based Tokenization
It split the input text into single characters.

This has two primary benefits:
The vocabulary is much smaller.
There are much fewer out-of-vocabulary (unknown) tokens, since every word can be built from characters.
But, this approach isn’t perfect either. Since the representation is now based on characters you could argue that, it’s less meaningful as character doesn’t mean a lot on its own.
One way to handle this issue is using:
02. Word-Based Tokenization
It is the most straightforward tokenization technique, it splits the input text into words based upon the whitespace between them and find a numerical representation for each of them.
For instance, as shown in the image:

Let's develop a simple tokenizer based on some sample text of our data.
The following regular expression will split on whitespaces:

The result is a list of individual words, whitespaces, and punctuation characters.
There are also variations of word tokenizers that have extra rules for punctuation, as shown in image below:

Let's modify the above regular expression splits on whitespaces (\s) and commas, and periods ([,.]):

This looks pretty good.
But, let's modify it a bit further so that it can also handle other types of punctuation, such as question marks, quotation marks, and the double-dashes, along with additional special characters:

Cool!
If you appreciate this effort, hit that Subscribe button, so you don’t miss when I put out any new posts!
Creating Tokens IDs From Token
Next, we need to convert the preprocessed tokens into integer token IDs, later these integers can be embedded into LLM as input.
Below image illustrates the tokenization of a short sample text using a small vocabulary:
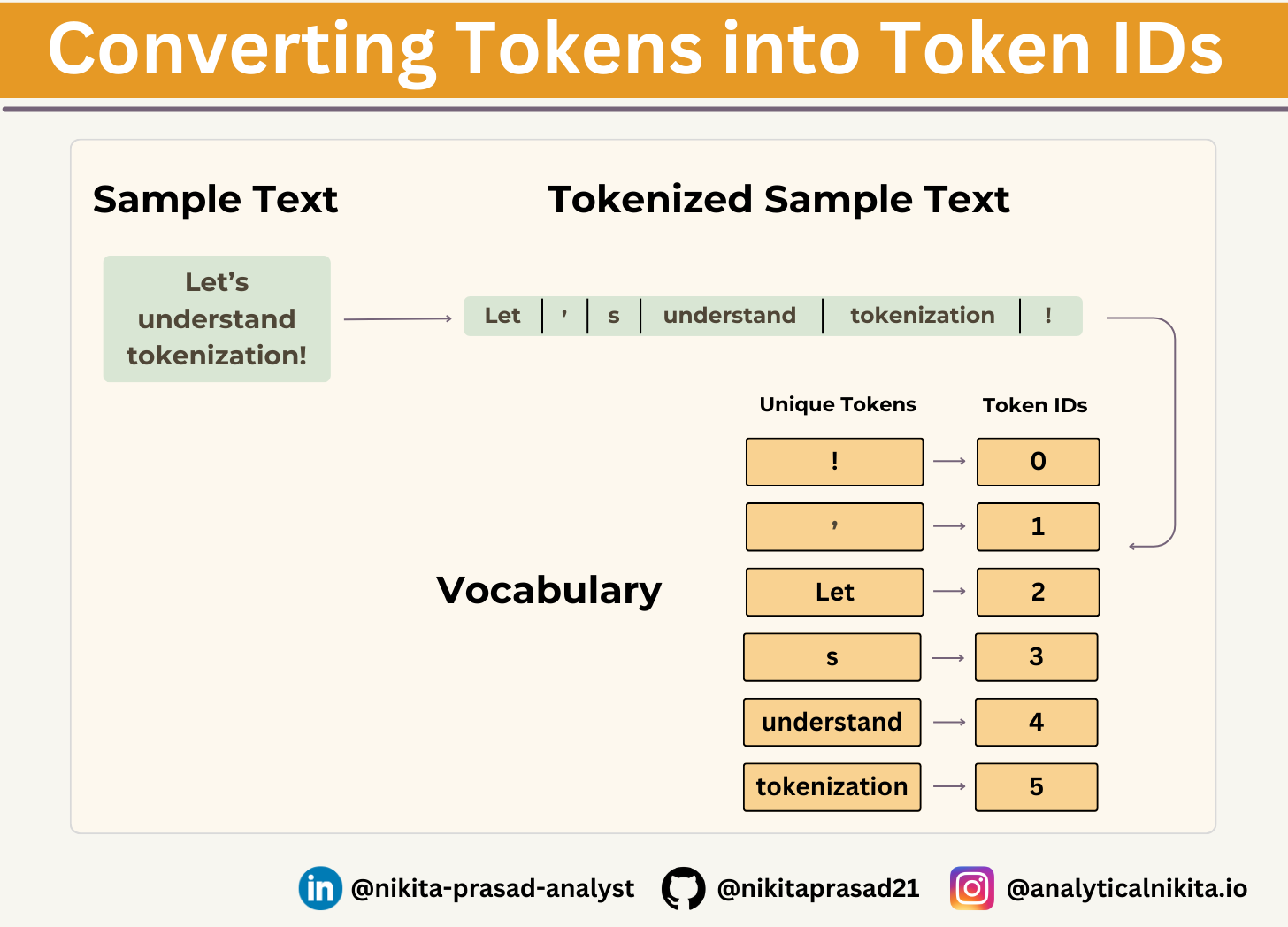
For this first let's sorts the unique tokens from the preprocessed_tokens list and calculates the size of the resulting vocabulary.

The vocabulary size of our dataset is 6155.
Now, we have to create a vocabulary, using our unique_tokens:
vocab = {token:index for index, token in enumerate(unique_tokens)}This dictionary contains individual tokens associated with unique integer labels.
Later, when we want to convert the outputs of an LLM from numbers back into text, we also need a way to turn token IDs into text.
For this, we can create an inverse version of the vocabulary that maps token IDs back to corresponding text tokens.
Now, putting it now all together to
» Implement a Simple Tokenizer class in Python:
The class will have an encode method that splits text into tokens and carries out the string-to-integer mapping to produce token IDs via the vocabulary.

In addition, we implement a decode method that carries out the reverse integer-to-string mapping to convert the token IDs back into text.

Following steps are implemented in the below code snippet:
Step 1: Store the vocabulary as a class attribute so that it is accessed by the encode and decode methods
Step 2: Create an inverse vocabulary that maps token IDs back to the original text tokens
Step 3: Process input text into token IDs, also called Encoding
Step 4: Convert token IDs back into text, also called Decoding
Step 5: Replace spaces before the specified punctuation to get better results

Let's instantiate a tokenizer object of SimpleTokenzier class and tokenize our sampled input text:
tokenizer = SimpleTokenizer(vocab)
ids = tokenizer.encode(sampled_input_text)
print(ids)The code above prints the following token IDs:
# Output: [15, 2744, 726, 6135, 4018, 7, 6005, 2957, 3042, 546, 1217, 3946, 5494, 1982, 7, 3251, 4555, 3949, 726, 3949, 12, 1, 28, 5905, 0, 28, 5905, 0, 382, 0, 431, 4, 4708, 691, 4645, 0, 1]Next, let's see if we can turn these token IDs back into text using the `decode` method:
tokenizer.decode(ids)
# Output: 'A green and yellow parrot, which hung in a cage outside the door, kept repeating over and over:" Allez vous-en! Allez vous-en! Sapristi! That' s all right!"'Bravo! Based on the output above, we can see that the decode method successfully converted the token IDs back into the original text.
However, we’ve just scraped the tip of the iceberg.
So far, so good.
We implemented a tokenizer capable of tokenizing and de-tokenizing text based on a snippet from the training set.
Let's now apply it to a new text sample that is not contained in the training set:
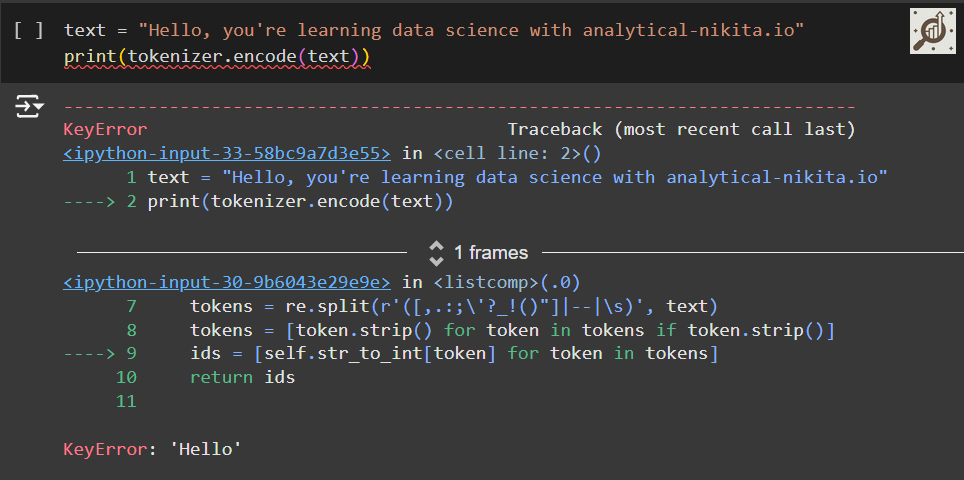
The problem is that the word "Hello" was not used in the, The Awakening short story.
Hence, it's not present in the vocabulary.
This highlights the need to consider large and diverse training sets to extend the vocabulary when working on LLMs.
Let’s solve this problem:
Adding Special Context Tokens
We can modify the tokenizer to use an <|unk|> token, if it encounters a word that is not part of the vocabulary.
Furthermore, we add a special token <|endoftext|> between unrelated texts. For example, when training LLMs like GPT-2 they also used <|endoftext|> on multiple independent documents and books.
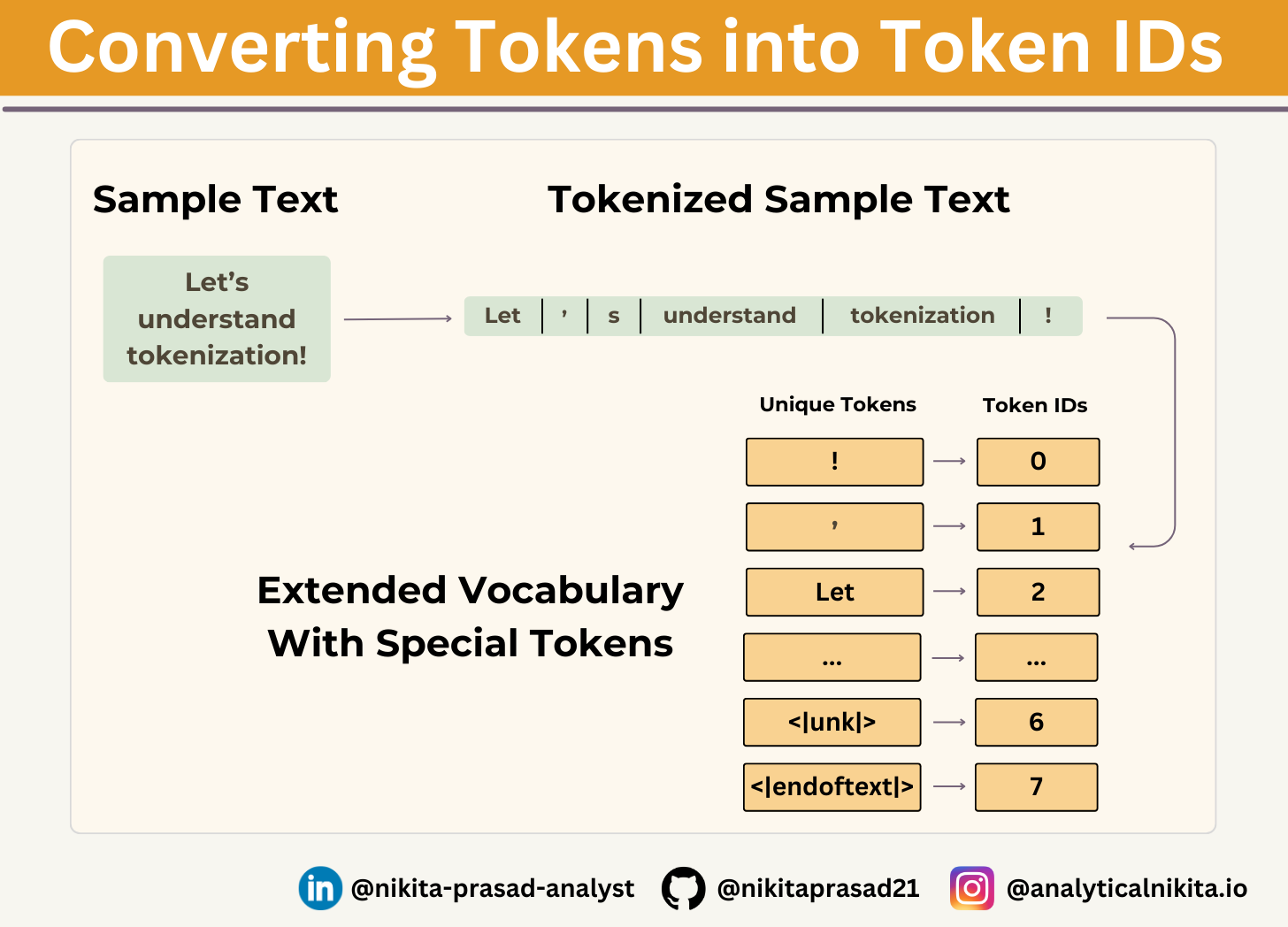
Let's now modify the vocabulary to include these two special tokens, i.e, <|unk|> and <|endoftext|>, by adding these to the previously created list of all unique words :
unique_tokens = sorted(list(set(preprocessed_tokens)))
unique_tokens.extend(["<|endoftext|>", "<unk>"])
vocab = {token:index for index, token in enumerate(unique_tokens)}Now, let's modify our
» Simple Text Tokenizer that handles Unknown Words
This code snippet, has one modifications, in the previous version of Simple Tokenizer:
Modification 1: Replace unknown words by <|unk|> tokens

Let’s instantiate a tokenizer object for SimpleTokenzierToHandleUnknowns class :
tokenzier = SimpleTokenzierToHandleUnknowns(vocab)
text1 = "Hello, you're learning data science with analytical-nikita.io"
text2 = "In the sunlit terraces of the palace."
text = " <|endoftext|> ".join((text1, text2))
# Encoding
tokenzier.encode(text)
# Output : [6156, 7, 6144, 4, 4426, 6156, 6156, 6156, 6067, 6156, 10, 6156, 6155, 231, 5494, 6156, 6156, 3892, 5494, 6156, 10]
# Decoding
tokenzier.decode(tokenzier.encode(text))
# Output : '<unk>, you' re <unk> <unk> <unk> with <unk>. <unk> <|endoftext|> In the <unk> <unk> of the <unk>.'Based on comparing the de-tokenized text above with the original input text, we know that the training dataset, Kate Chopin's short story, The Awakening, did not contain the words like "Hello", "learning", "data", "science", "analytical”, “nikita’, “io", etc.
Even though, we get an output but it’s generally a bad sign if you see that the tokenizer is producing a lot of <unk> tokens, as it wasn’t able to retrieve a sensible representation of a word and you’re losing information along the way.
This is the major drawback of this technique, including :
Large Vocabulary Issue: A word-based tokenizer needs a unique ID for every word, resulting in a very large vocabulary (e.g., 500,000+ words in English).
Unique IDs for Words: Each word, including variations like "toy" and "toys", gets a unique ID, with no initial understanding of their similarity.
Morphological Challenges: Words like "eat", “eating” and "eaten" are treated as unrelated, limiting the model's ability to generalize word relationships.
Unknown Token ([UNK] or <unk>): Frequent use of OOV word indicates poor tokenization and information loss.
Our goal is to build an efficient vocabulary, that the tokenizer tokenizes as few words as possible into the unknown token.
One way to reduce the amount of unknown tokens is to get the best of both worlds.
GPT-2 model uses a Byte-Pair Encoding Tokenizer, which breaks down words into sub-word tokens, which we will discuss next!
Note: Depending on the LLM, some researchers also consider additional special tokens such as the following:
[BOS] (Beginning Of Sequence): This token signifies about the start of a text to the LLM.
[EOS] (End Of Sequence): Similar to
<|endoftext|>,this token is positioned at the end of a text, and is especially useful when concatenating multiple unrelated texts.[PAD] (Padding): While training LLMs with batch sizes larger than one, the batch might contain texts of varying lengths, to ensure all texts have the same length, the shorter texts are extended or "padded" using the [PAD] token, up to the length of the longest text in the batch.
If you’d like to explore the full implementation, including code and data, then checkout: Github Repository. 👈🏻
And that’s a wrap, if you enjoyed this deep dive, stay tuned with ME, so you won’t miss out on future updates.
Until next time, happy learning!