

How LLMs Embeds Input Tokens?
Detailed Walkthrough of How LLMs Process and Embed Texts.

In the initial phase of the input processing workflow, the input text is segmented into separate tokens using tiktoken library.
Following this read, you can understand “how” and “why” tokens are transformed into token IDs based on a pre-defined vocabulary. 👇🏻
Sub-Word Tokenization Using Byte-Pair Encoding

Previously, we implemented a simple tokenization class.
If you’re new here, I would appreciate if you, subscribe me and stick around to dive deeper into AI & ML tips and insights.
Despite of having token ids we need token embeddings to capture the semantic relation between the tokens, to capture the meaning of the text and semantic similarity within them.

Why Token Embeddings Are Important?
Token embeddings helps in creating the semantic relation between words/ tokens by creating vectors, which captures the relationship or closeness or difference between two words.
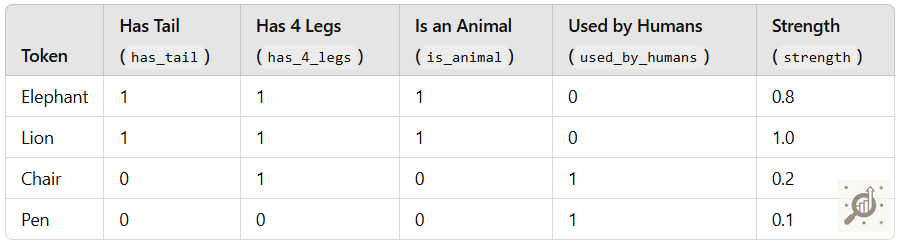
For instance, to represent the semantic relationships between words like elephant, lion, chair, and pen, we can create a word embedding with dimensions that capture key features or attributes.
Let's define five dimensions that align with the characteristics of these tokens:
To visualize the semantic relationships in 2D as shown in below graph, you can perform dimensionality reduction (e.g., PCA or t-SNE) on these embeddings.
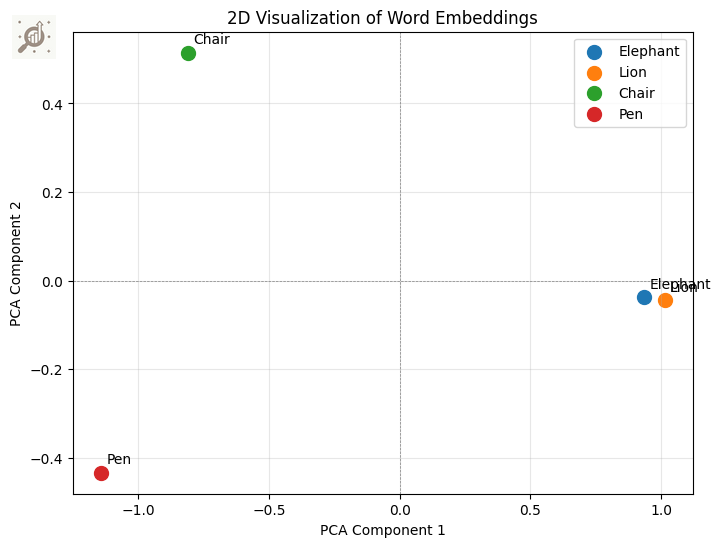
Here is the 2D visualization of the word embeddings:
Elephant and Lion are positioned close together, reflecting their shared animal traits.
Chair and Pen cluster away from the animals, highlighting their shared human-use attributes.
The scatter plot captures these semantic relationships based on the defined dimensions, providing a clear view of their similarities and contrasts between the tokens.
But, now the question is:
How do you come up with these Vector Embedding?
The answer is simple, we need to train a Large Neural Network to create vector embeddings.
But this is a computationally expensive task.
Example: word2vec-google-news-300, is pre-trained vectors that is trained on a part of the Google News dataset (about 100 billion words). It has 300-dimensional vectors for 3 million words and phrases.
Let’s dive deep to understand:
How are Token Embeddings created for LLMs?
The data is already almost ready for a LLM. We have created the vocabulary, now we are ready to to convert TokenIDs into embedding layer.
But before that, let us embed the tokens in a continuous vector representation using an embedding layer.
Usually, these embedding layers are part of the LLM itself. The first step is to initialize the embedding weights with random values.
Note: This initialization serves as the starting point for LLM learning process. Embedding weights are optimized (trained) during model training.
Suppose we have the following four input examples with input ids 5, 3, 7 and 2 (after tokenization):
input_ids = torch.tensor([5, 3, 7, 2])For the sake of simplicity, suppose we have a small vocabulary of only 9 words and we want to create embeddings of size 3:
vocab_size = 9
output_dim = 3
torch.manual_seed(123)
embedding_layer = torch.nn.Embedding(vocab_size, output_dim)This would result in a 9x3 weight matrix:
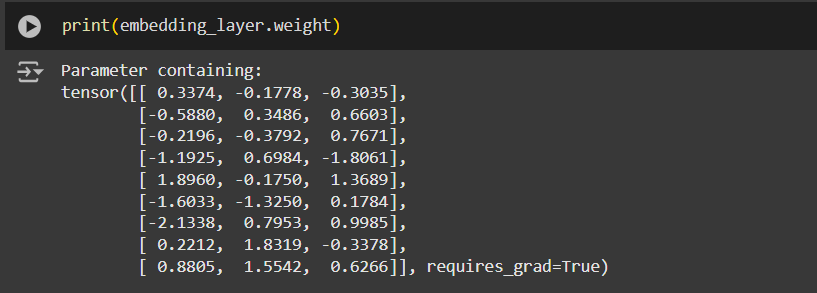
Note: If you're familiar with one-hot encoding, the embedding layer approach above is essentially just a more efficient way of implementing one-hot encoding followed by matrix multiplication in a fully-connected neural network layer that can be optimized via backpropagation.
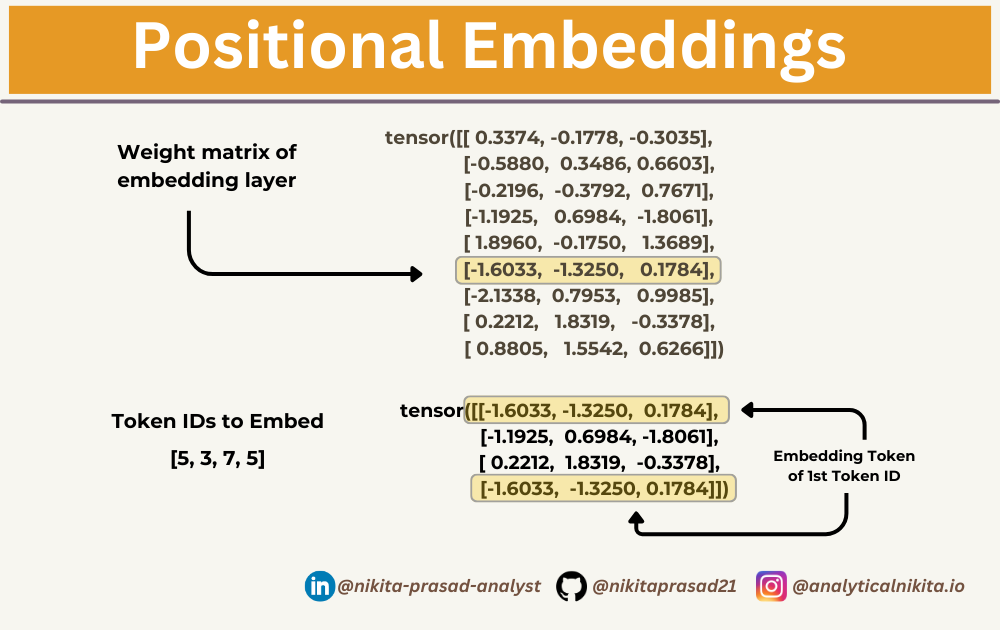
To convert a token with id 3 into a 3-dimensional vector, we do the following:
print(embedding_layer(torch.tensor([3])))
# Output: tensor([[-1.1925, 0.6984, -1.8061]], grad_fn=<EmbeddingBackward0>)Note: The above is the only the 4th row in the embedding_layer weight matrix. So, to embed all four input_ids values above, we do:
print(embedding_layer(input_ids))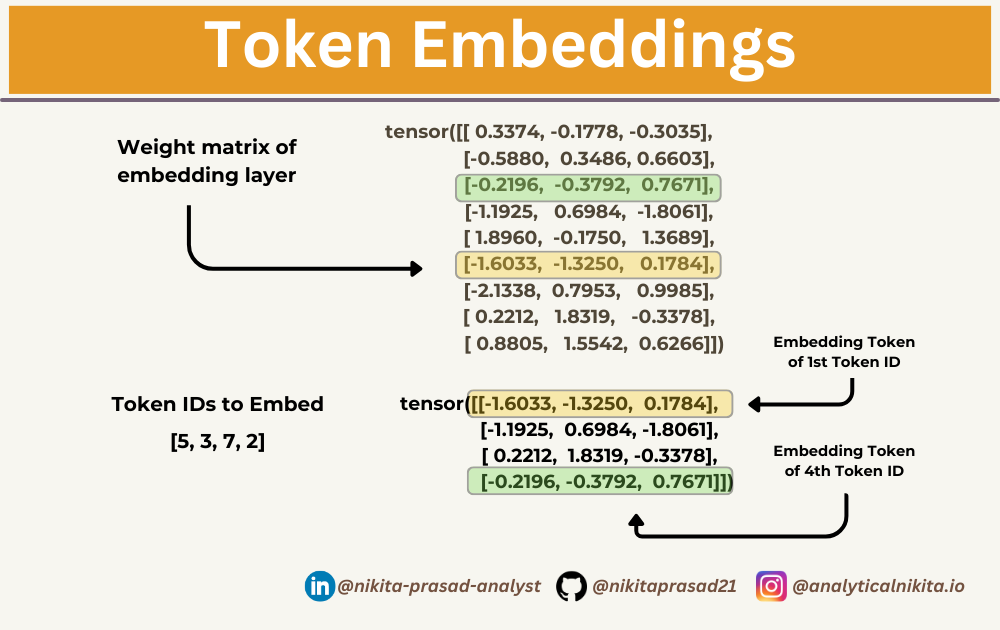
Essentially, the embedding layer is a lookup operation that retrieves rows from the embedding layer weights matrix using token IDs.
For, GPT-2 (Small), the vector dimension is 768 and vocabulary size is 50257.
The BytePair Encoder, which we built here, has a vocabulary size of 50,257:
Suppose, we want to encode the input tokens into a 256-dimensional vector representation:
vocab_size = 50257
output_dim = 256
token_embedding_layer = torch.nn.Embedding(vocab_size, output_dim)If we have a batch size of 8 with 3 tokens each, this results in a 8 x 3 x 256 tensor:
max_length = 3
dataloader = dataloader_v1(
input_text, batch_size=8, max_length=max_length,
stride=max_length, shuffle=False
)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)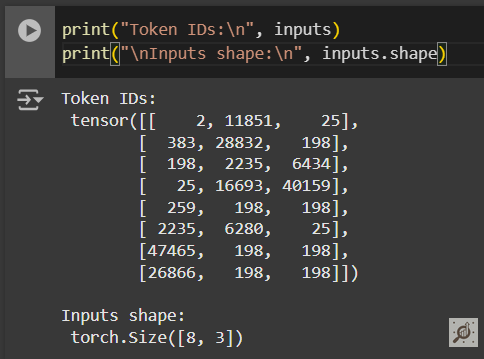
token_embeddings = token_embedding_layer(inputs)
print(token_embeddings.shape)
# Output: torch.Size([8, 3, 256])Now that we are set with our token embeddings, we need to create position embeddings before creating the final input embeddings.
What are Positional Embeddings?
In embedding layer, the same token ID gets mapped to same vector representation, regardless where the token ID is positioned in the input sequence.
It is important to exploit the additional positional information to the LLM, to get the maximum information about the text.
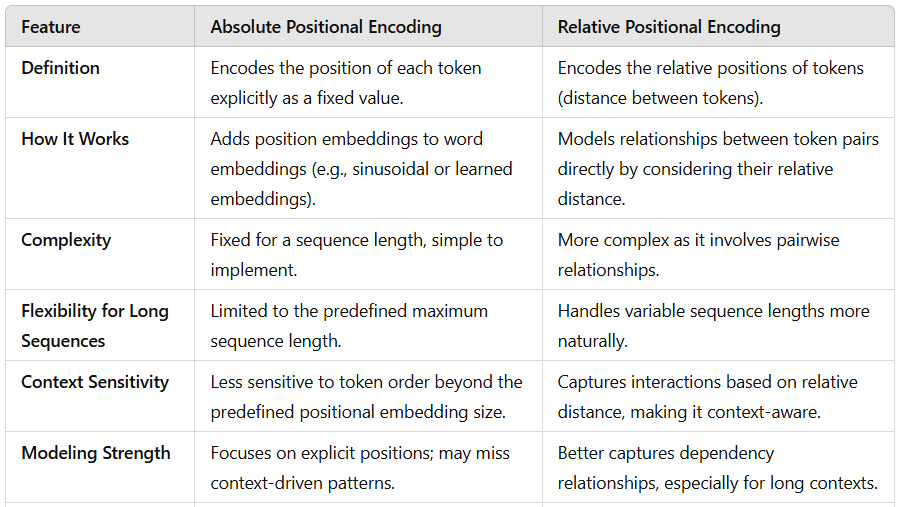
There are two major types of positional encoding: Absolute and Relative Positional Encoding.
Here’s a difference table:
Now you may wonder,
What is used by GPT-2?
So, GPT-2 uses absolute positional encoding with learned embeddings.
This is because GPT-2's architecture processes fixed-length input sequences (up to 1024 tokens in the default model), making absolute encoding simpler and efficient for its design.
Note: 1. Absolute Positional Encoding is suitable when explicit-order of tokens order are priorities, especially for shorter or fixed-length sequences.
2. Relative Positional Encoding is suitable when dealing with long or variable-length sequences, as it captures dependencies better and avoids constraints of predefined lengths.
context_length = max_length
positional_embedding_layer = torch.nn.Embedding(context_length, output_dim)pos_embeddings = positional_embedding_layer(torch.arange(max_length))
print(pos_embeddings.shape)
# Output: torch.Size([3, 256])To create the input embeddings used in an LLM, we simply add the token and the positional embeddings:
input_embeddings = token_embeddings + pos_embeddings
print(input_embeddings.shape)
# Output: torch.Size([8, 3, 256])Later, while training the LLM, we’ll extend the max_length of tokens.
Putting It All Together
LLMs Data Preprocessing Pipeline is consists of four major steps:
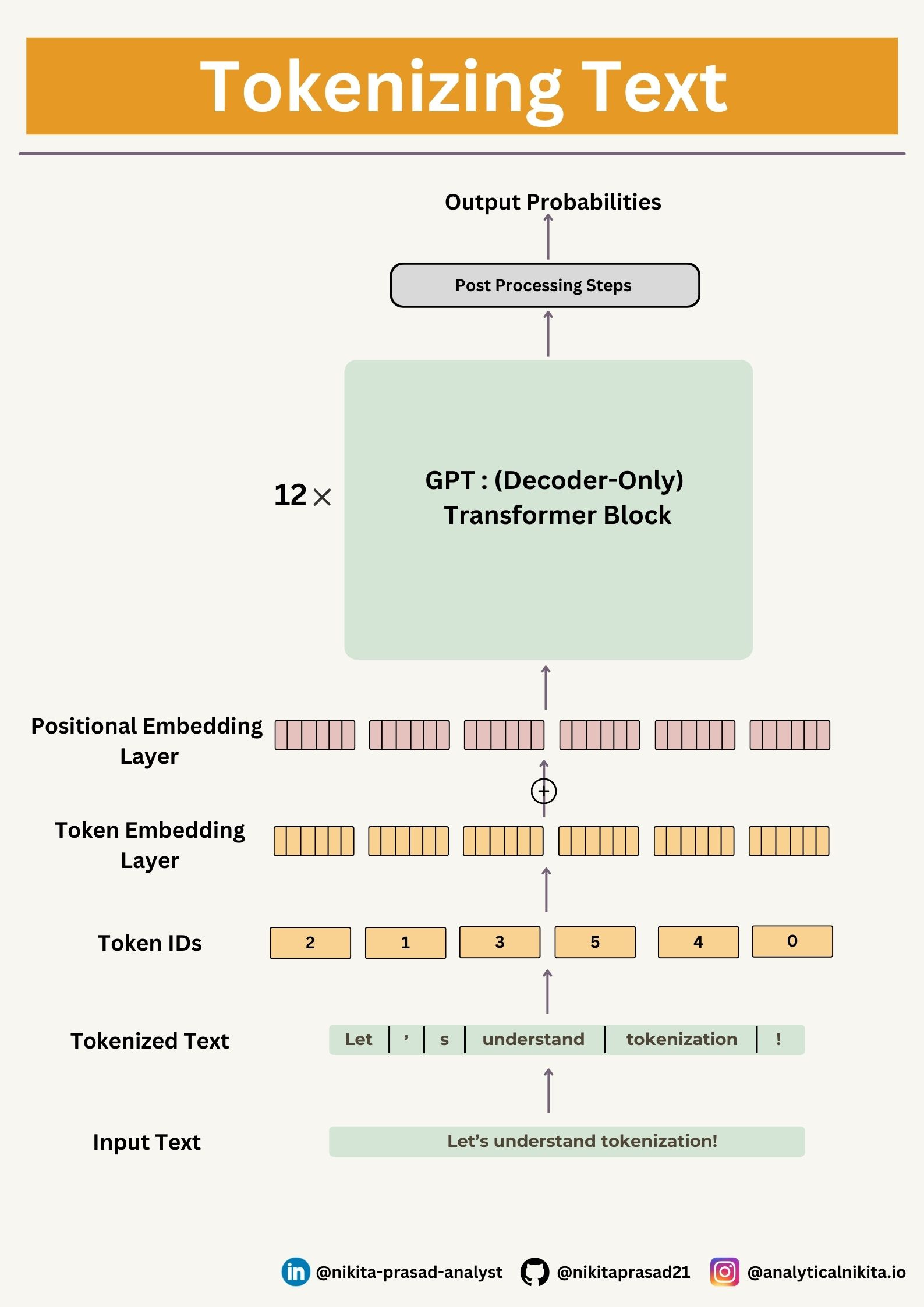
Tokenization: Splitting input text in list of tokens (vocabulary)
Token Embeddings: Converting token IDs to vector embeddings
Positional Embeddings: Encoding positional information of each vector
Input Embeddings: It is the addition of Token and Positional Embeddings
Now these Input Embeddings are feed to the LLM transformer.
Stay tuned, as next we’ll dive into Attention Mechanism of GPT-2.
If you’d like to explore the full implementation, including code and data, then checkout: Github Repository 👈🏻
And that’s a wrap, if you enjoyed this deep dive, stay tuned with ME, so you won’t miss out on future updates.
Until next time, happy learning!